Détection des fraudes bancaires : comment adapter des règles métiers déterministes pour un modèle IA multivarié ?
Comment détecter des activités bancaires suspectes ?
Les limitations des systèmes existants de détection de fraude.
Les paiements en ligne se sont multipliés ces dernières années, tout comme les cas de fraudes. Les fraudeurs s’adaptent aux règles déterministes mises en place initialement et parviennent à trouver puis exploiter les failles du système. Système qui la plupart du temps se présente sous forme d’outil d’analyse de dépassement de seuils préalablement choisis. Par exemple, si l’utilisateur effectue un virement bancaire avec une somme anormalement haute sur un compte inconnu, l’équipe d’analyse de risque sera alertée pour investiguer davantage et conclure quant à l’aspect frauduleux ou non.
Cependant, si le fraudeur connaît ces règles de seuils, il effectuera alors de nombreuses transactions à faible montant afin de passer sous les radars. Une fois ce nouveau type de fraude détecté, le système ajustera ses règles pour palier à ce problème.
Un problème majeur est que le système de détection doit répondre aux failles trouvées par les fraudeurs et aura donc un temps de retard. D’autre part, le système ne permet pas d’évaluer le niveau de risque. Si les valeurs des seuils sont trop restrictives, beaucoup de transactions frauduleuses ne seront pas détectées. Mais si les seuils sont trop larges, l’équipe d’analyse de risque sera alors submergée par les transactions à investiguer.
La solution sense4data : adapter les règles expertes pour un modèle IA
Sense4data a travaillé en étroite collaboration avec une équipe d’experts afin de traduire ces règles métiers dans une approche d’intelligence artificielle. Un des enjeux majeurs est de construire un modèle qui permettra de répondre aux limitations des seuils et d’ordonner les transactions selon un niveau de risque décroissant, de sorte que les équipes d’analyses se focalisent sur les activités les plus suspectes.
Contrairement à la majorité des solutions existantes basées sur de l’IA, l’approche développée par sense4data est appelée « non supervisée ». C’est-à-dire qu’aucun historique de fraude connue n’est nécessaire. Ce parti pris est motivé d’une part, car le travail d’annotation de l’équipe d’analyse de risque est long et fastidieux. D’autre part, les techniques de fraudes évoluent dans le temps et les règles de décision apprises par un modèle dit supervisé aura du mal à généraliser sur des futures techniques qui n’apparaissent pas dans le jeu de données annotées.
Le cœur de la solution développée par sense4data réside dans la construction d’un comportement moyen de chacun des utilisateurs bancaires. L’algorithme s’appuie sur l’historique des activités pour déterminer par exemple les horaires habituels de connexions, sa fréquence de transactions en ligne, etc. Une fois ce comportement moyen construit, l’algorithme est capable de mesurer en temps réel si la session en cours sort de l’ordinaire et à quel point cette activité est usuelle pour cet utilisateur en particulier. L’atout de cette approche, dite multivariée, est qu’elle évalue le caractère exceptionnel selon des centaines d’indicateurs combinés (appelés features) et non pas un par un, par rapport à des valeurs seuils prédéterminées et non personnalisées.
À quoi sert l’algorithme Isolation Forest ? Scoring et interprétabilité
Le modèle utilisé pour calculer un score de risque est l’Isolation Forest [1]. Ce modèle a montré de bonnes performances pour différents problèmes de détection d’anomalies. Dans notre cas, une grande majorité des transactions sont bénignes. Les fraudes peuvent donc être considérées comme des anomalies. Le principe de l’Isolation Forest est que si on découpe notre espace de features de manière aléatoire, une anomalie sera probablement isolée plus rapidement que les autres points.
Considérons un exemple en deux dimensions, où chaque transaction X est représentée selon deux features. Dans la figure suivante (source [1]), le découpage aléatoire de l’espace de points requiert plus d’itérations pour isoler le point bleu (11) que le point rouge (4).
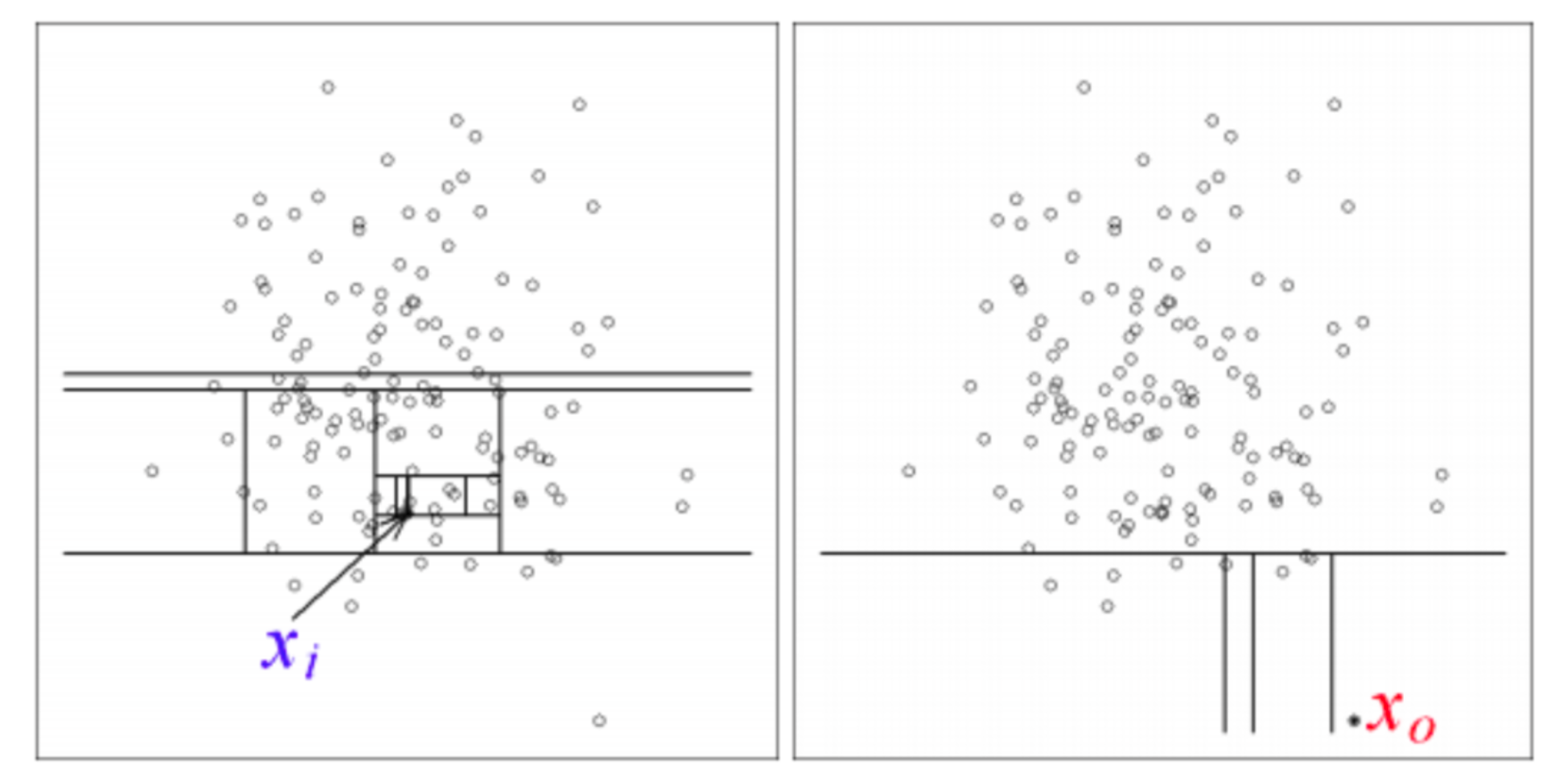
L’interprétation est que le point rouge représente probablement une anomalie. Le caractère aléatoire de l’Isolation Forest fait que le nombre d’itérations peut varier. C’est pourquoi l’algorithme effectue en parallèle plusieurs découpages aléatoires (construction d’arbres) puis le score final est moyenné comme illustré dans la figure ci-dessous (source [1]).
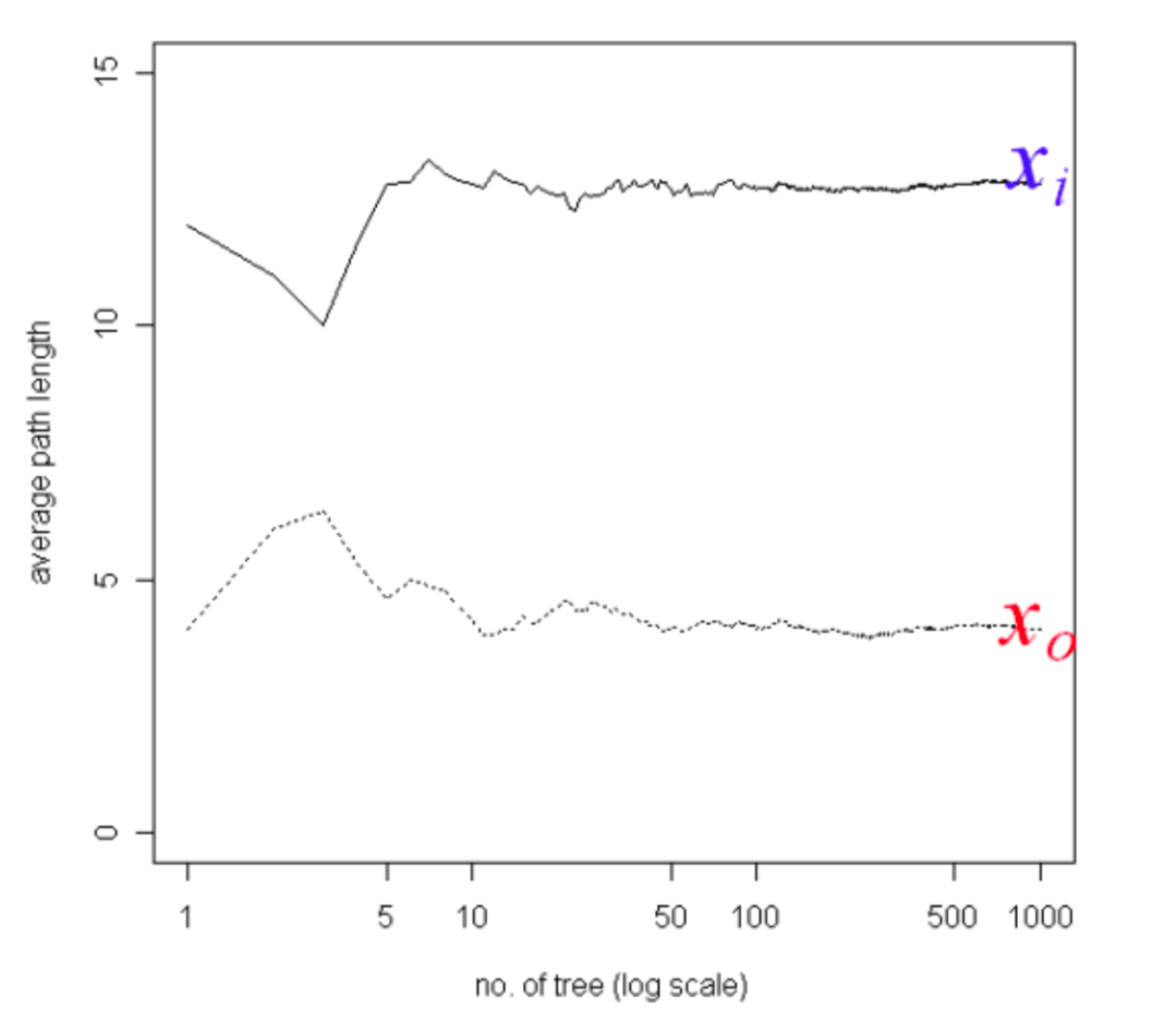
Le score de risque final du point bleu apparaît plus élevé que le point rouge. En pratique, la dimension (nombre de features) est de plusieurs centaines. Le score est calculé pour l’ensemble des points (transactions) et l’algorithme remonte à l’équipe d’analyse de risque les scores les plus élevés à investiguer en priorité. De plus, la solution développée par l’équipe Sense4data s’appuie sur ses compétences en interprétabilité pour apporter automatiquement des axes d’investigation.
Cette approche permet de détecter toutes sortes d’activités qui sortent de l’ordinaire de manière personnalisée. La collaboration avec une équipe experte en fraude bancaire et les compétences IA chez sense4data ont permis de construire un algorithme robuste aux techniques de fraude futures. À moins de reproduire l’exact comportement de l’utilisateur, toute session à risque sera détectée.
Plus généralement, sense4data est capable d’adresser des problématiques « non supervisées » complexes (clustering, détection d’anomalies…).
Pour en savoir plus sur l’éventail des compétences au sein de sense4data, cliquez ici.