Le NLP ou comment mesurer la proximité de sens de deux phrases sans aucun mot en commun ?
Introduction à la sémantique
La tâche de similarité sémantique est une sous-tâche de la tâche Paire de phrases qui consiste à comparer une paire de textes et à déterminer une relation entre eux.
Dans notre cas, cette paire de textes est une paire de phrases grammaticales, dont nous essayons de déterminer la relation sémantique. C’est-à-dire, ces deux phrases sont-elles synonymes ? Antonymes ? Ou plutôt sans aucune relation sémantique ?
sense4data propose l’utilisation de la similarité sémantique dans son algorithme de Job Seeker Matching (Sense4Matching) afin de comparer les compétences décrites par les candidats dans leur CV avec celles demandées dans l’offre d’emploi. Cela permet de calculer le taux de compatibilité entre l’offre et le CV.
Différentes approches
Approche par mots-clés
Une première approche consiste à comparer les mots contenus dans les deux textes et à calculer un score de similarité en fonction du nombre de mots en commun.
La méthode de notation la plus courante est l’indice de Jaccard, de formule :
Jaccard (A, B)∈ [0, 1] = || A∩B |||| AUB ||
Soit la paire de phrases (A, B) suivante:
A: Suivi de la construction
B: Suivi du chantier de construction
L’indice jaccard (A, B) obtenu est de 0. Ceci est justifié par le fait que les deux phrases sont totalement différentes d’un point de vue formel : elles n’ont aucun mot en commun. Cependant, ce sont des phrases très similaires d’un point de vue sémantique. On peut donc dire que le calcul de la similarité entre deux phrases d’un point de vue morphologique n’est pas suffisant. Il est nécessaire d’examiner les phrases à partir de leur sens.
Extensions lexicales
Une des techniques permettant de mesurer la proximité du sens de deux phrases n’ayant aucun mot en commun et de répondre aux limites des approches par « mots-clés » est l’utilisation d’embeddings lexicaux. Ces derniers, également appelés embeddings, sont des représentations mathématiques des mots, sous forme de vecteurs dans un espace multidimensionnel.
L’un des premiers modèles conçus à cette fin est Word2Vec [1], développé par Google sous la direction de T. Mikolov en 2013. Ce modèle, composé de réseaux de neurones à deux couches, est entraîné à produire, pour les mots partageant le même contexte, des vecteurs numériques spatialement proches. Les vecteurs résultant de l’entraînement sont des vecteurs statiques.
Comme il s’agit de vecteurs mathématiques, il est possible d’effectuer des opérations algébriques (addition, soustraction, etc.) pour en déduire des relations.
Prenons les mots « maman », « papa », « femme », « homme », nous pouvons en déduire la relation suivante :
maman = papa – homme + femme
Les vecteurs Word2Vec ont été calculés de manière à ce que cette équation puisse être vraie en utilisant les vecteurs correspondants.
La figure suivante représente un ensemble de mots codés avec l’algorithme Word2Vec. Une réduction de dimensionnalité [2] a été appliquée aux vecteurs résultants pour les représenter dans un espace bidimensionnel.
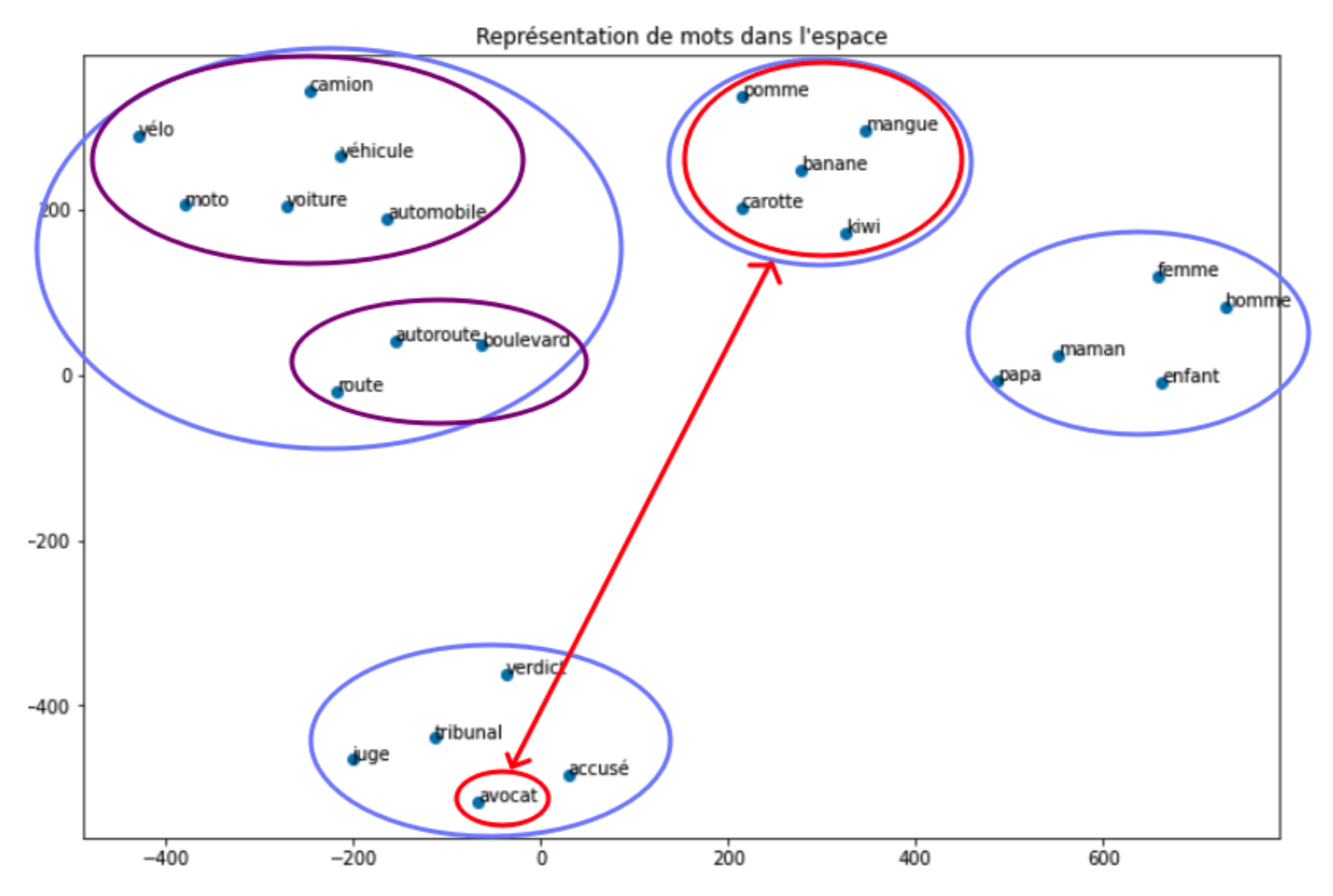
Nous observons que la plupart des mots faisant référence au même champ lexical sont très proches dans l’espace. C’est le cas de mots comme « mangue », « banane », qui renvoient à la même idée : la nourriture.
Prenons toutefois le cas du mot ambigu « avocat « , qui peut être, selon le contexte, un fruit ou un individu exerçant une fonction juridique. Nous constatons qu’il est inclu dans le champ lexical juridique mais à une grande distance du champ lexical alimentaire.
Modèles contextuels
Afin de résoudre le problème mentionné ci-dessus et d’obtenir une représentation plus efficace et significative des mots, différents modèles ont vu le jour ces dernières années. Ces modèles dits contextuels permettent d’obtenir, pour un mot donné d’une phrase, une représentation vectorielle calculée en fonction des mots qui l’entourent, au lieu d’un vecteur fixe.
Parmi les modèles développés dans ce but, BERT [3] est celui qui a révolutionné le monde du traitement automatique du langage naturel, en battant plusieurs records sur des tâches basées sur le langage.
Qu’est-ce que le modèle BERT et comment fonctionne-t-il ?
BERT (Bidirectional Encoder Representations from Transformers) est un modèle de langage développé par Google en 2018. Il est plus performant que ses prédécesseurs en termes de résultats et de vitesse d’apprentissage. Une fois pré-entraîné en non supervisé, il peut être affiné pour effectuer une tâche plus spécifique avec peu de données.
Ce modèle basé sur des transformateurs bidirectionnels peut traiter diverses tâches telles que la traduction automatique, le balisage PoS, la génération de texte, la similarité sémantique, etc.
Un transformateur est un modèle qui prend une phrase en entrée et en produit une autre en sortie. Il se compose d’un nombre égal d’encodeurs et de décodeurs.
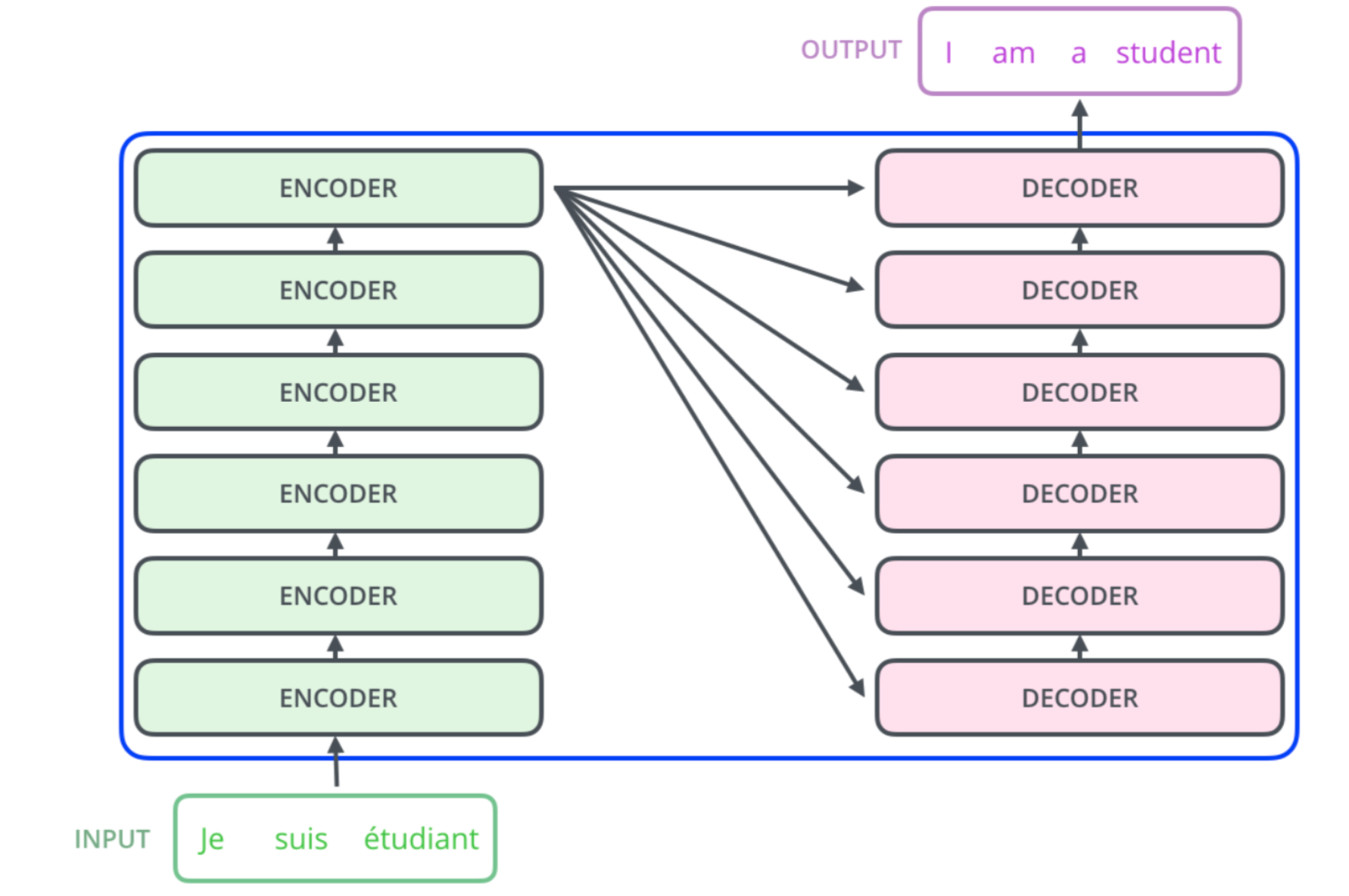
Tous les codeurs ont une architecture identique, illustrée dans la figure ci-dessous.
Ils sont chacun composés d’une couche d’auto-attention et d’un réseau neuronal à action directe [4].
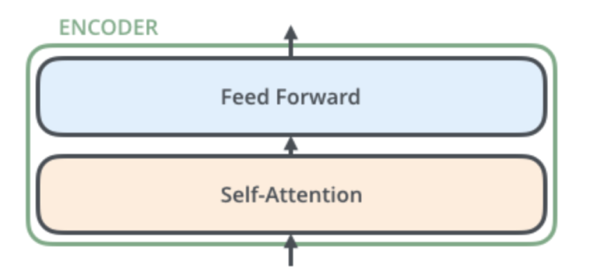
Le mécanisme d’auto-attention permet à un codeur de communiquer avec d’autres codeurs et de comprendre quels mots de la séquence d’entrée sont les plus pertinents pour aider à générer la meilleure représentation vectorielle du mot actuel. Ainsi, quels mots de la séquence d’entrée sont les plus pertinents contextuellement et sémantiquement pour le mot en cours d’encodage. Chaque encodeur peut donc consulter les mots du passé et du futur.
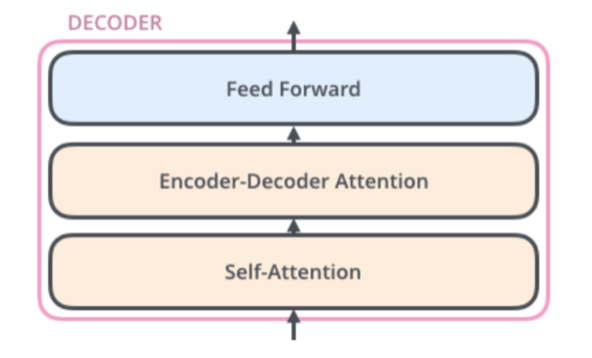
Les décodeurs possèdent également ces deux couches, sauf qu’entre les deux, il existe une autre couche appelée attention de l’encodeur et du décodeur qui permet la communication entre les encodeurs et les décodeurs.
Ce mécanisme d’attention permet aux décodeurs de comprendre quels mots de la séquence d’entrée sont les plus pertinents pour générer un mot de sortie. Chaque décodeur ne consulte que les mots des positions précédentes pour générer le mot actuel puisque le futur n’est pas encore prédit.
L’architecture des décodeurs est présentée dans la figure ci-dessous :
BERT n’utilise qu’une partie de l’architecture des Transformers. En effet, comme son nom l’indique, il est composé d’une pile de blocs encodeurs bidirectionnels, sans décodeurs. Il prend en entrée une séquence de tokens (mots, signes de ponctuation, etc.) qui passent par ces couches d’encodeurs et produit en sortie une séquence de vecteurs contextuels.
BERT est disponible en deux modèles :
le modèle de base avec 12 encodeurs
grand modèle avec 24 encodeurs.
Pour plus d’informations sur les Transformers et BERT, voir les articles de J. Alammar [5] et P. Denoyes [6] sur le sujet.
Représentation vectorielle de la phrase
Comme vu précédemment, la sortie du modèle BERT est une liste de vecteurs correspondant aux représentations vectorielles des tokens de la phrase d’entrée. Pour obtenir un encastrement unique pour l’ensemble de la phrase, de nombreuses méthodes peuvent être appliquées telles que la moyenne des vecteurs de mots, leur addition…
La méthode que nous allons privilégier est celle qui utilise le modèle Sentence-BERT (S-BERT) développé par Reimers et Gurevych [6].
S-BERT est une version modifiée du modèle BERT dans laquelle des réseaux BERT siamois ont été introduits. Cela facilite la représentation des phrases, des paragraphes et des images sous une forme vectorielle. Le texte est codé dans un espace vectoriel de sorte que les textes ayant la même signification sont spatialement proches et peuvent être identifiés à l’aide de la distance cosinus.
La distance ou similarité en cosinus est un score de similarité entre deux vecteurs à n dimensions. Elle détermine la valeur du cosinus de leur angle.
Soit deux vecteurs A et B, on a comme formule :
Cosinus (A, B)∈ [-1, 1] = A.B|| A || || B ||
- Plus le cosinus est proche de 1, plus les phrases sont synonymes,
- Plus il est proche de -1, plus les phrases sont opposées,
- Plus il est proche de 0, moins il existe de relation sémantique entre les phrases.
S-BERT est proposé avec un large panel de modèles pré-entraînés.
L’algorithme Sense4Matching utilise celui entraîné avec des réseaux BERT siamois multilingues.
Cela permet de capturer la similarité sémantique des compétences décrites dans la même langue, ainsi que celles décrites dans des langues différentes. Par conséquent, cela permet de traiter des documents sans mots en commun et de ne pas faire de discrimination entre des CV dont les formulations des compétences/expériences sont différentes de celles de l’offre. C’est notamment le cas des CV techniques et des offres d’emploi, dans lesquels un grand nombre de termes anglais sont utilisés.
Voici des exemples de résultats obtenus en déterminant la similarité sémantique entre les compétences via S-BERT et la similarité cosinus :
A : Accompagnement des travaux de construction
B : Supervision de la construction
cosinus (A, B) = 0.79
C : Génération de graphiques
D: Production de dessins
cosinus (C, D) = 0.72
E : Correction des défauts
F : Correction des anomalies
cosinus (E, F) = 0.67
G : Natural language processing
H : Natural language processing
cosine (G, H) = 0.78
I : Gestion de projet
J : Gestion de projets
cosinus (I, J) = 0.97
Conclusion
Il existe de nombreuses tâches pour lesquelles la similarité sémantique peut être utilisée. Elle peut être utilisée pour :
- Améliorer les résultats d’un moteur de recherche,
- Construire un système de recommandation pour les articles de presse,
- Aider le support client à trouver plus rapidement des réponses aux questions, notamment grâce aux chatbots.,
- Améliorer un site web/produit en regroupant les commentaires des clients sur le même thème,
etc.
Grâce à ses compétences en intelligence artificielle, Sense4data est en mesure d’apporter des solutions à toutes ces tâches, mais aussi de répondre aux problématiques du traitement automatique du langage naturel en général. En effet, la société est en mesure de fournir aux équipes des outils permettant d’automatiser des tâches qui seraient répétitives, coûteuses en temps et en ressources humaines sur différentes thématiques du NLP telles que : l’extraction d’informations, la classification de documents, la génération automatique de textes, la reconnaissance d’entités nommées, etc.
Pour en savoir plus sur l’éventail des compétences au sein de sense4data, cliquez ici.
Bibliographie
[1] Tomas Mikolov (2013), Efficient Estimation of Word Representations in Vector Space
[2] https://fr.wikipedia.org/wiki/Algorithme_t-SNE
[3] Zell, Andreas (1994), Simulation Neuronaler Netze [Simulation of Neural Networks]
[4] https://jalammar.github.io/illustrated-transformer/
[5] Nils Reimers, Iryna Gurevych (2019), Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks