Ontologie des métiers : pourquoi le référentiel dynamique des emplois et des compétences est-il essentiel ?
Les sites d’emploi en ligne sont devenus une référence majeure pour l’acquisition de talents et la recherche d’emploi. Ces portails d’emploi ont donné lieu à des problèmes difficiles de correspondance et de recherche. La correspondance ou la recherche de base se fait entre les compétences, les professions et les qualifications requises pour le poste et celles présentes dans le profil du candidat. La longue liste de compétences professionnelles et sa nature polyonyme rendent la correspondance directe par mot-clé moins efficace. Il en résulte une correspondance de qualité inférieure ou des résultats de recherche qui ne tiennent pas compte d’un candidat correspondant étroitement au poste parce qu’il ne possède pas les mêmes compétences. Il est important d’utiliser une mesure de la similarité sémantique entre les compétences pour améliorer la pertinence des résultats.
Cet article propose une mesure de la similarité sémantique entre les compétences et les emplois par une approche basée sur la connaissance métier. Cette connaissance peut être représentée par un graphe d’ontologie.
Qu’est-ce qu’une ontologie ?
En informatique, une ontologie est un modèle de données qui représente un ensemble de concepts dans un domaine et les relations entre ces concepts. Par exemple, en intelligence artificielle, en génie logiciel, en informatique biomédicale et en architecture de l’information, une ontologie est définie comme une forme de représentation des connaissances sur le monde.
Quels sont les processus de construction d’une ontologie ?
Sense4data propose l’utilisation de graphes d’ontologie dans son logiciel de mise en correspondance des demandeurs d’emploi et des offres d’emploi, afin de résoudre les problèmes mentionnés ci-dessus. Cette approche se caractérise par l’utilisation d’ontologies d’emploi existantes telles que ESCO [1] et Onet [2] et par leur enrichissement avec des données collectées sur des sites d’emploi en ligne tels que LinkedIn afin d’obtenir un score de similarité entre les compétences et les emplois. L’enrichissement est une mesure nécessaire pour permettre à notre ontologie de prendre en compte les changements et les évolutions possibles du marché du travail. L’ontologie permet également de résoudre le problème de la normalisation d’une compétence de base ou d’une profession à partir de ses multiples représentations.
Aperçu de l’ontologie obtenue
Le graphe construit est caractérisé par différents types d’arêtes qui définissent les types de relations entre les entités des nœuds, par exemple si une compétence est nécessaire ou facultative pour une certaine profession, ou si une profession est une sous-profession d’une autre, ou si une compétence est une sous-compétence d’une autre… Je vous recommande de parcourir les ontologies mentionnées dans cet article afin d’avoir une compréhension plus claire des différents types de nœuds et de relations que nous pourrions avoir sur notre graphe.
Ce graphe, à travers ses différents types de nœuds et de relations, fonctionne comme un dictionnaire, décrivant, identifiant et classant les professions, les compétences et les qualifications professionnelles pertinentes pour le marché du travail.
Processus de calcul de la similarité
Pour calculer la similarité entre 2 entrées (compétences ou professions), nous produisons une vectorisation de ces dernières à travers des modèles d’intégration de mots à la pointe de la technologie, tels que Bert [3], Fasttext [4], puis nous projetons les 2 entrées sur notre graphe ontologique à partir de la similarité en cosinus [5] calculée entre chacune des vectorisations des entrées et tous les nœuds du graphe précédemment vectorisés.
Une fois que chacune des entrées est positionnée sur les nœuds relatifs aux scores de similarité en cosinus les plus élevés, nous calculons la distance entre ces nœuds dans le graphe en utilisant des algorithmes de graphe basés sur l’intelligence artificielle.
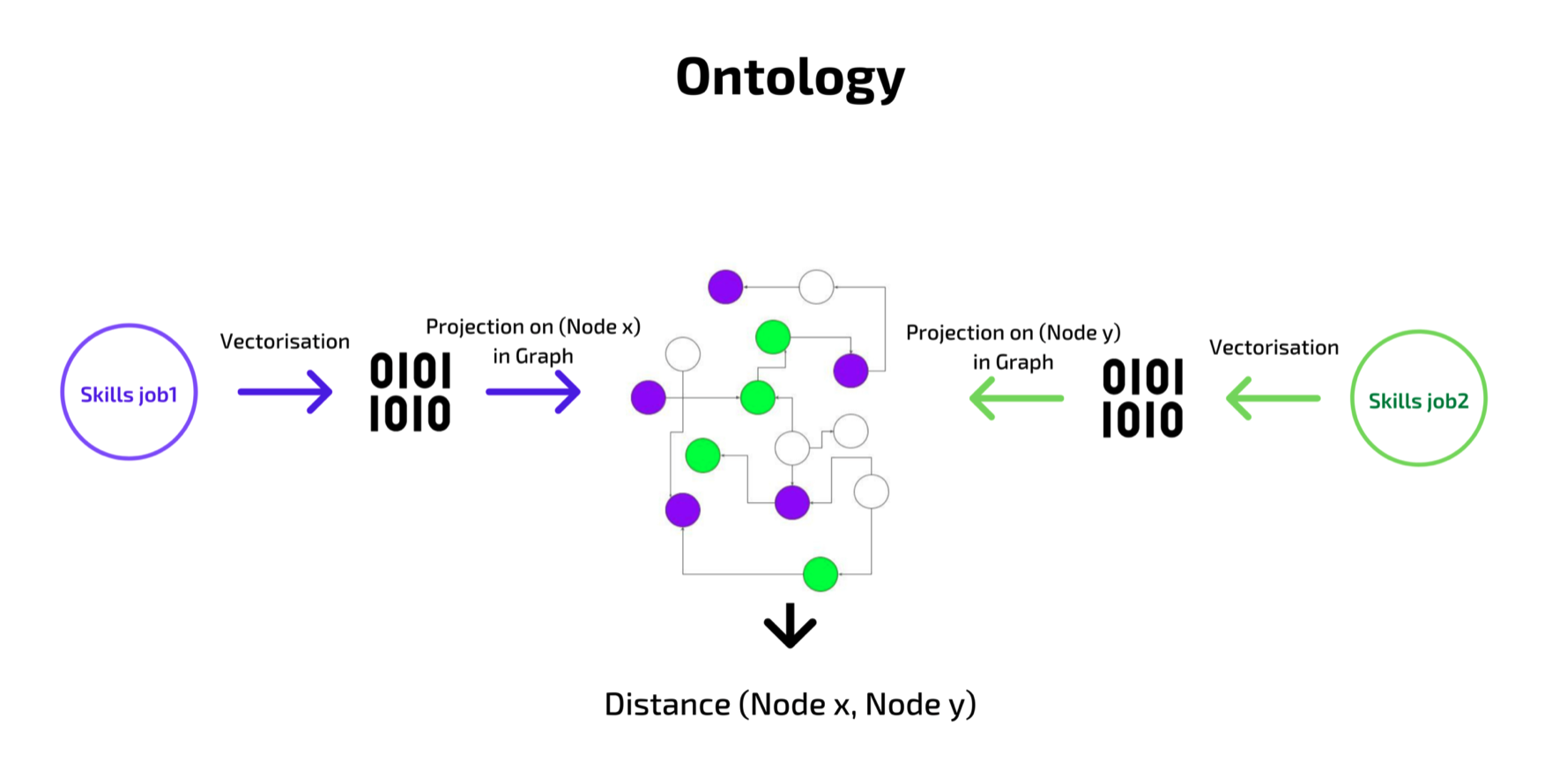
Présentation du modèle d’ontologie des emplois et des compétences
Cette distance représente à la fois la proximité lexicale et sémantique et la proximité du point de vue du marché du travail.
Au-delà d’un calcul de similarité représentatif entre deux entités du lexique du marché du travail, cette ontologie, par son enrichissement continu, permettra de suivre l’évolution du marché du travail, telle que :
- Identification des compétences et professions émergentes.
- Identification des compétences et des métiers qui disparaissent.
- Identification des proportions géographiques des métiers.
En plus de répondre aux exigences du poste annoncé, d’autres facteurs tels que les préférences des demandeurs d’emploi et des recruteurs, l’adéquation culturelle, la capacité à s’adapter au marché de l’entreprise et la capacité à évoluer avec l’organisation jouent un rôle important dans la sélection des employés. Et enfin, sur la base des connaissances intégrées dans notre ontologie, une fonctionnalité de proposition de formation a été mise en place afin d’acquérir de nouvelles compétences pour évoluer vers d’autres opportunités de carrière ou vers une reconversion professionnelle.
Chez sense4data, nous privilégions l’utilisation de la théorie des graphes. Étant donné un ensemble de nœuds et de connexions, qui peut résumer l’abstraction du problème, la théorie des graphes fournit un outil utile pour quantifier et simplifier les nombreuses parties mobiles des systèmes dynamiques. L’étude des graphes à travers un cadre fournit des réponses à de nombreux problèmes d’agencement, de mise en réseau, d’optimisation, de correspondance et de classement. La théorie des graphes peut être utilisée pour modéliser de nombreux types de relations et de processus dans les systèmes physiques, biologiques, sociaux et d’information, et a un large éventail d’applications utiles telles que :
- Classement des liens dans les moteurs de recherche.
- Cartes GPS pour trouver le chemin le plus court d’un endroit à un autre.
- Sécurité des réseaux informatiques
- Recherche de communautés dans les réseaux
Pour en savoir plus sur l’éventail des compétences au sein de sense4data, cliquez ici.
Bibliographie
[1] ESCO – Commission européenne – European Commission https://esco.ec.europa.eu/fr/about-esco [2] O*NET OnLine onetonline.org [3] Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html [4] fastText fasttext.cc [5] Cosine Similarity – Understanding the math and how it works machinelearningplus.com/nlp/cosine-similarity