Donner du sens aux prédictions : pourquoi l’interprétabilité et la transparence des algorithmes méritent d’être traitées par vos équipes data ?
Devrait-on toujours faire confiance aux modèles de prédiction utilisant le Machine Learning qui atteignent de hautes performances ? Par exemple, si un modèle très performant recommande un médicament spécifique pour traiter un patient, peut-on lui faire confiance aveuglément, ou ne serait-il pas préférable de comprendre les facteurs qui ont contribué à cette décision ?
Ce problème d’interprétabilité est récemment devenu prédominant dans le monde de l’IA.
Qu’est-ce que l’interprétabilité en machine learning ?
L’interprétabilité, c’est le degré avec lequel un humain peut comprendre ou prédire les prédictions d’un modèle. Dans l’exemple précédent, il serait tout aussi important de comprendre le diagnostic, ainsi que les symptômes du patient qui y ont contribué. En voyant ces explications, la confiance des utilisateurs dans ce modèle augmenterait, et celui-ci gagnerait en acceptance sociale.
Mais les avantages de l’interprétabilité ne s’arrêtent pas là. Nous l’utilisons notamment pour apprendre des règles métiers de nos données, détecter les biais que les modèles exploitent, mais aussi pour nous assurer que nos modèles ne discriminent pas de minorités et respectent les données sensibles.
L’interprétabilité en pratique chez sense4data
Souvent, une meilleure interprétabilité est atteinte en utilisant des modèles plus simples et moins performants, ce qui force leurs utilisateurs à choisir entre performance et compréhension de leurs modèles. Chez sense4data, nous préférons utiliser des techniques de pointe permettant l’interprétabilité de modèles de machine learning avancés, et nous permettant ainsi de conserver les meilleures performances possibles.
Un de nos algorithmes phares, dénommé SHapley Additive exPlanations (SHAP), se base sur la théorie des jeux pour calculer un score de contribution à la prédiction pour chacun des indicateurs. Ces scores sont distribués de manière équitable, de telle sorte qu’un score élevé traduit une contribution forte et un score nul est associé à un indicateur n’ayant aucun impact. Des scores SHAP négatifs sont aussi possibles, reflétant des indicateurs allant à l’encontre de la prédiction donnée par le modèle.
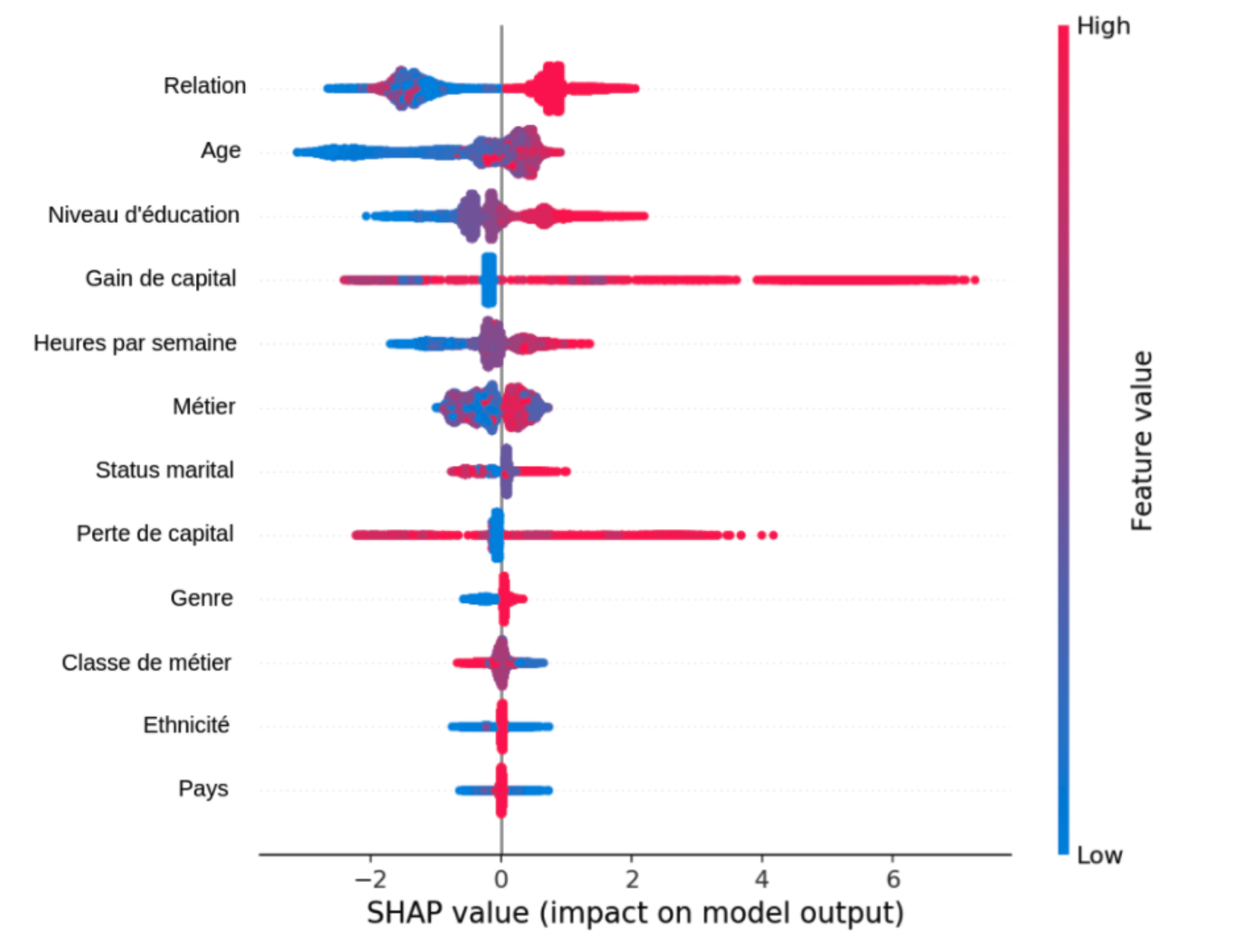
Ce graphique montre l’importance de différents indicateurs sur une tâche de prédiction de revenu annuel supérieur à $50k. Les valeurs SHAP positives (points sur la moitié droite) indiquent une contribution positive d’un indicateur. Par exemple, le modèle semble s’appuyer fortement sur le gain de capital pour prédire de hauts revenus. De plus, la couleur rouge (ou bleu) indique des valeurs hautes (ou faibles) pour chaque donnée d’entrée du modèle. Par exemple, le modèle semble avoir appris que l’âge, le niveau d’éducation et le nombre d’heures de travail par semaine sont positivement corrélés avec le revenu annuel. Par contre, l’ethnicité et le pays ne semblent avoir qu’un faible impact sur les prédictions.
Chez sense4data, nous utilisons ce genre d’algorithme et de visualisation pour comprendre et valider nos modèles, ainsi que les rendre plus robustes. Ils nous permettent aussi d’approfondir nos connaissances sur des problématiques spécifiques, qui, à leur tour, peuvent être utilisées pour améliorer nos processus et modèles. Ce cercle vertueux nous permet aussi de développer une confiance dans les solutions que nous livrons.
Pour en savoir plus sur l’éventail des compétences au sein de sense4data, cliquez ici.