P2SQL (Prompt-to-SQL) injection : Les risques des Injections SQL dans les applications web intégrant des Grands Modèles de Langage (LLMs)
Abstract :
L’intégration des grands modèles de langage (LLMs) dans les applications web a considérablement transformé l’expérience utilisateur en ligne. Des entreprises comme Google, Facebook et Amazon utilisent déjà des LLMs pour améliorer leurs moteurs de recherche, leurs chatbots de service client et leurs systèmes de recommandation. Par exemple, le service de streaming Netflix utilise des modèles de langage pour améliorer ses algorithmes de recommandation, offrant ainsi des suggestions plus personnalisées et contextuelles aux utilisateurs. De même, des plateformes de commerce électronique comme Shopify ont intégré des LLMs pour générer des descriptions de produits, améliorant ainsi la pertinence et l’engagement des clients.
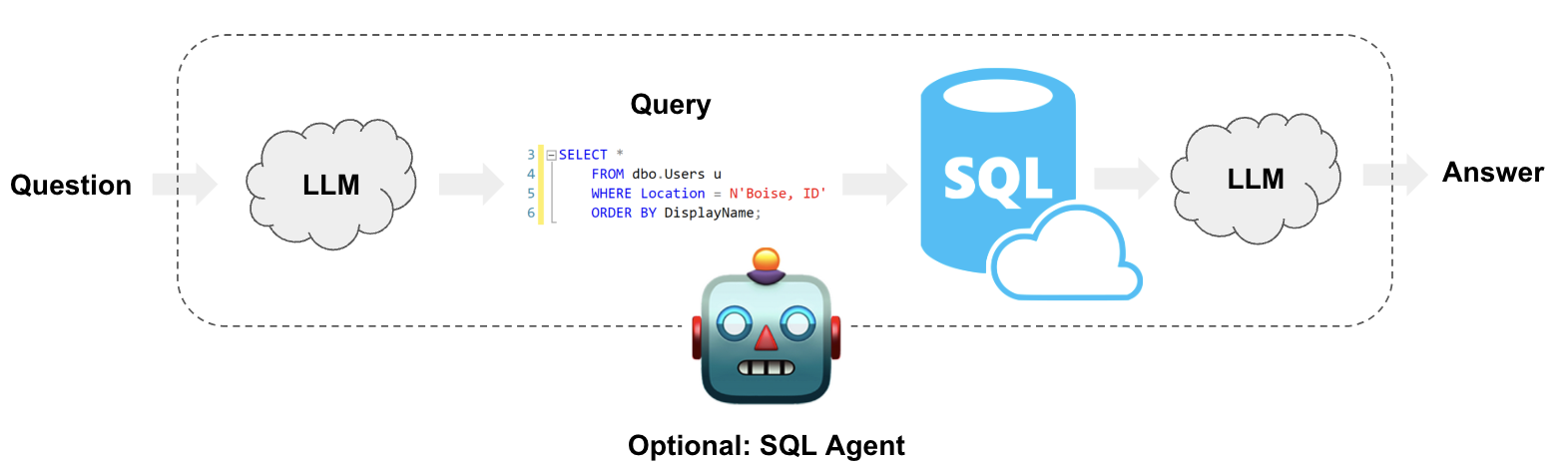
Cependant, cette adoption croissante des LLMs dans l’industrie n’est pas sans risques. L’un des problèmes de sécurité les plus préoccupants est la vulnérabilité aux attaques par injection SQL via des prompts de LLM : les hackers utilisent le Prompt-to-SQL « P2SQL » pour exploiter les failles de votre infrastructure. Alors pour représenter à quoi cela pourrait ressembler, imaginons une application de réservation de vols qui utilise un LLM pour interagir avec les utilisateurs. Si le modèle n’est pas correctement sécurisé, un utilisateur malveillant pourrait insérer une requête SQL malveillante dans le prompt, ce qui pourrait compromettre la base de données de l’application et exposer des informations sensibles telles que les détails de paiement des clients.
Bien que des recherches aient été menées pour évaluer et atténuer ces risques, plusieurs défis et limitations demeurent. Par exemple, les mécanismes de défense actuels, tels que les filtres d’entrée, se sont avérés inefficaces dans le contexte des LLMs, comme le montrent des études récentes. De plus, la plupart des recherches se concentrent sur des modèles de langage spécifiques, ce qui limite la généralisabilité des résultats et des solutions.
Donc s’il est clair que les LLMs offrent des avantages considérables en termes de fonctionnalités et d’expérience utilisateur, leur intégration dans les applications web doit être abordée avec prudence. Les risques de sécurité, notamment les attaques par injection SQL, nécessitent une attention particulière de la part des développeurs et des chercheurs.
Généralisabilité des résultats
La question de la généralisabilité des résultats est un défi majeur dans l’étude des risques de sécurité associés à l’intégration des grands modèles de langage (LLMs) dans les applications web. Actuellement, de nombreuses études, y compris des travaux académiques et des rapports industriels, se concentrent sur des cadres spécifiques de LLM, y compris certaines librairies python comme Langchain. Bien que ces études fournissent des informations précieuses, elles ne capturent qu’une petite fraction du paysage diversifié des LLMs.
Prenons l’exemple de deux géants technologiques à l’état de l’art, Google et OpenAI. Google utilise son modèle BERT (Bidirectional Encoder Representations from Transformers) pour diverses applications, y compris la recherche et la réponse aux questions, tandis qu’OpenAI a développé GPT-3, qui est utilisé dans des domaines allant de la génération de texte à la traduction. Ces modèles diffèrent non seulement dans leur architecture – BERT utilise des Transformers bidirectionnels tandis que GPT-3 utilise des Transformers unidirectionnels mais aussi dans leur approche de la sécurité. Par exemple, GPT-3 peut avoir des mécanismes de modération de contenu intégrés qui ne sont pas présents dans BERT.
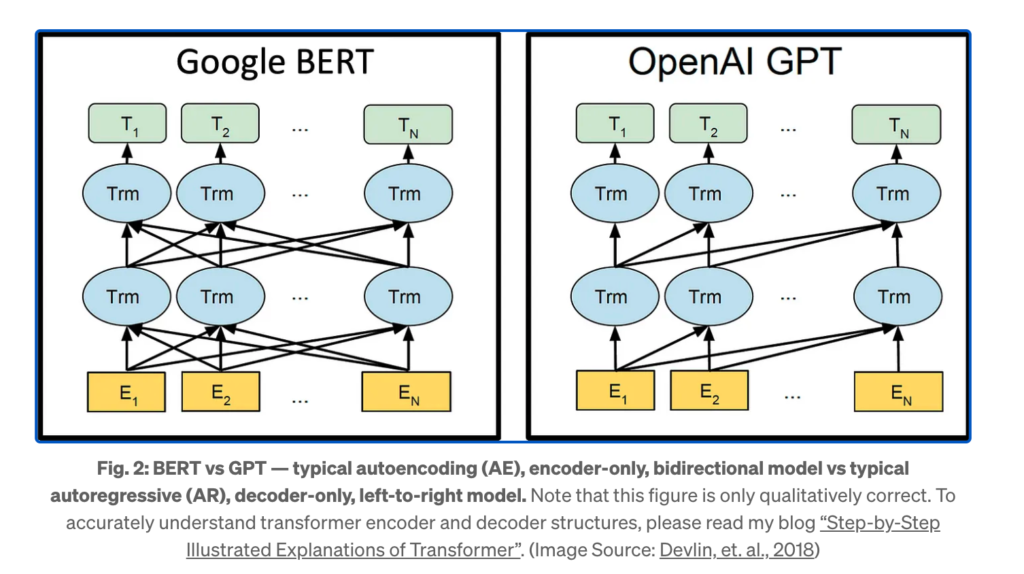
Ces différences architecturales et fonctionnelles peuvent avoir un impact significatif sur la vulnérabilité des modèles aux attaques par injection SQL. Un mécanisme de défense qui fonctionne bien pour Langchain pourrait être totalement inefficace pour BERT ou GPT-3. De plus, les entreprises ont souvent recours à des versions personnalisées de ces modèles, adaptées à des besoins spécifiques, ce qui peut introduire de nouvelles vulnérabilités ou atténuer celles existantes.
En conséquence, il est impératif que les études futures adoptent une approche plus holistique, englobant une variété de cadres de LLM et de configurations. Cela permettrait non seulement de mieux comprendre les risques de sécurité associés à l’utilisation des LLMs dans les applications web, mais aussi de développer des mécanismes de défense plus robustes et généralisables. Une telle approche serait particulièrement bénéfique pour les organisations qui utilisent plusieurs types de LLMs dans différentes parties de leur infrastructure, garantissant ainsi une sécurité plus uniforme à travers leurs applications.
Efficacité des mécanismes de défense contre les injections P2SQL
L’inefficacité des mécanismes de défense traditionnels, tels que les restrictions de prompts, dans le contexte des grands modèles de langage (LLMs) est une préoccupation majeure pour la sécurité des applications web. Les approches de « filtrage d’entrée » ont longtemps été la pierre angulaire de la défense contre les injections SQL dans les applications traditionnelles. Cependant, ces méthodes semblent être inadéquates lorsque les LLMs entrent en jeu.
Prenons l’exemple d’une application de service client automatisée utilisée par une grande banque. Cette application pourrait utiliser un LLM pour interagir avec les clients et accéder à la base de données pour récupérer des informations sur les comptes. Si un utilisateur malveillant découvre que le modèle est vulnérable aux injections SQL, il pourrait formuler un prompt qui semble inoffensif mais qui, une fois traité par le LLM, se transforme en une requête SQL malveillante. Cela pourrait permettre à l’attaquant d’accéder à des informations sensibles, telles que les soldes de compte ou les historiques de transaction.
Ce scénario met en évidence la nécessité de repenser les mécanismes de défense dans le contexte des LLMs. Les modèles de langage, en raison de leur capacité à comprendre et à générer du langage naturel, introduisent une nouvelle dimension de complexité qui n’était pas présente dans les applications web traditionnelles. Par exemple, un LLM pourrait interpréter une phrase ambiguë d’une manière qui conduit à une injection SQL, même si la phrase passerait à travers des filtres d’entrée classiques.
Il est donc impératif de développer des mécanismes de défense plus sophistiqués et spécifiques au contexte des LLMs. Ces mécanismes pourraient inclure des techniques d’apprentissage en profondeur pour détecter les tentatives d’injection SQL, ou des approches basées sur l’analyse sémantique pour comprendre le contexte dans lequel un prompt est donné. On pourrait dire « naïvement », qu’une combinaison de plusieurs techniques pourrait s’avérer nécessaire pour fournir une défense robuste contre les injections SQL dans les applications web qui intègrent des LLMs.
Portée de l’évaluation des modèles
La limitation de la portée de l’évaluation des modèles dans les études actuelles constitue un obstacle majeur à une compréhension complète des risques de sécurité associés aux grands modèles de langage (LLMs) dans les applications web. Souvent, les recherches se concentrent sur une poignée de LLMs de pointe, négligeant ainsi un éventail plus large de modèles qui sont également utilisés dans l’industrie et la recherche.
Pour illustrer ce point, considérons l’exemple de deux entreprises du secteur de la santé qui utilisent des LLMs pour aider au diagnostic médical. La première entreprise pourrait utiliser un modèle comme GPT-3, qui est généraliste et largement utilisé, tandis que la seconde pourrait opter pour un modèle spécialisé dans le domaine médical, comme BioBERT. Ces deux modèles, bien qu’utilisés pour des tâches similaires, ont des architectures et des jeux de données d’entraînement différents, ce qui pourrait entraîner des vulnérabilités spécifiques à chaque modèle. Par exemple, BioBERT pourrait être moins susceptible aux injections SQL liées à des termes médicaux en raison de son entraînement spécialisé, tandis que GPT-3 pourrait être plus vulnérable en raison de son caractère généraliste.
De plus, les LLMs sont souvent fine-tunés (le fine-tuning est une branche du transfer learning, c’est à dire que les poids d’un modèle pré-entrainé sont utilisés sur de nouveaux jeux de données) pour des tâches ou des domaines spécifiques, ce qui peut soit introduire de nouvelles vulnérabilités, soit renforcer les mécanismes de défense existants. Par exemple, un modèle fine-tuned pour une application de commerce électronique pourrait être plus résistant aux injections SQL liées à des termes de produit, mais plus vulnérable à d’autres types d’attaques.
- exemple d’attaque ciblant le processus de paiement : « ‘; DROP TABLE Transactions;– » dans un champ d’adresse.
- exemple d’attaque ciblant des utilisateurs particuliers : « ‘; SELECT * FROM Users WHERE username=’admin’;– » dans un champ de recherche d’utilisateurs.
Il est donc crucial que les études futures adoptent une approche plus exhaustive dans l’évaluation des modèles de langage, en tenant compte de la diversité des architectures, des domaines d’application et des configurations. Cette approche permettrait non seulement de mieux comprendre les risques associés à l’utilisation de LLMs dans différentes applications web, mais aussi de développer des stratégies de défense plus robustes et adaptées à différents contextes. Une telle démarche serait particulièrement utile pour les entreprises qui déploient des LLMs dans des environnements hétérogènes, garantissant ainsi une meilleure sécurité à travers leurs diverses applications et services.
Robustesse des tests expérimentaux
La robustesse des tests expérimentaux est un autre domaine qui nécessite une attention particulière dans l’évaluation des risques de sécurité associés aux grands modèles de langage (LLMs) dans les applications web. Actuellement, de nombreuses études évaluent les mécanismes de défense dans le contexte d’une seule application pratique, souvent dans un environnement contrôlé. Cette approche est insuffisante pour évaluer l’efficacité des mécanismes de défense dans des conditions du monde réel. Soyons honnêtes : il y’a des risques de sécurité et il y’en aura toujours.
Prenons l’exemple d’une plateforme de médias sociaux qui utilise un LLM pour générer des réponses automatiques aux questions des utilisateurs. Dans un environnement de test, le modèle pourrait sembler sécurisé contre les injections P2SQL. Cependant, dans des conditions du monde réel, des facteurs tels que le bruit dans les données d’entrée, la latence réseau et les contraintes de ressources du serveur pourraient affecter la performance du modèle et exposer des vulnérabilités non détectées lors des tests initiaux. Par exemple, une latence élevée pourrait entraîner des timeouts qui interrompent les mécanismes de défense, permettant ainsi des attaques réussies. Factuellement, les tests de sécurité doivent être aussi proches que possible des conditions réelles pour être le plus efficace.
Gardons en tête que les applications web modernes sont souvent complexes et composées de multiples microservices, chacun pouvant intégrer un type différent de LLM. Une évaluation qui ne prend en compte qu’une seule application ou un seul service ne capture pas la complexité et les interactions possibles qui pourraient affecter la sécurité globale de l’application. Par exemple, un mécanisme de défense efficace dans un service de chatbot pourrait être inutile dans un service de recherche intégré à la même application.
Il est donc impératif que les études futures incluent des tests de robustesse et des études de cas multiples pour évaluer l’efficacité des mécanismes de défense. Cela pourrait impliquer des tests en conditions réelles, des simulations de différents types d’attaques et l’évaluation de la performance des mécanismes de défense dans des configurations variées. Une telle approche multidimensionnelle permettrait d’obtenir une image plus complète de la robustesse des mécanismes de défense, contribuant ainsi à renforcer la sécurité des applications web qui intègrent des LLMs.
Conclusion : vers une compréhension plus complète des risques et des solutions contre les injections P2SQL
L’intégration des grands modèles de langage (LLMs) dans les applications web a ouvert la voie à des avancées significatives en termes de fonctionnalités et d’expérience utilisateur. Cependant, cette intégration a également introduit des risques de sécurité substantiels, notamment en ce qui concerne les injections SQL et dans notre cas, aux injections Prompt-to-SQL. Bien que des efforts de recherche aient été déployés pour évaluer et atténuer ces risques, plusieurs défis et limitations persistent.
Premièrement, la généralisabilité des résultats actuels est limitée, souvent en raison d’une focalisation sur des modèles ou des cadres spécifiques. Cela est particulièrement préoccupant étant donné la diversité des LLMs utilisés dans l’industrie, allant de modèles généralistes comme GPT-3 à des modèles spécialisés comme BioBERT pour des applications médicales. Chaque modèle présente des vulnérabilités et des mécanismes de défense uniques qui nécessitent une évaluation distincte.
Deuxièmement, les mécanismes de défense actuels, tels que les restrictions de prompts, se sont avérés inefficaces. Cela remet en question la viabilité des approches de « filtrage d’entrée » traditionnelles dans le contexte des LLMs. Des mécanismes de défense plus sophistiqués, qui tiennent compte de la complexité et de la nature générative des LLMs, sont donc nécessaires.
Troisièmement, la portée limitée de l’évaluation des modèles dans les études actuelles ne permet pas une compréhension complète des risques associés. Les LLMs sont souvent fine-tunés pour des tâches spécifiques, ce qui peut introduire de nouvelles vulnérabilités ou renforcer les défenses existantes. Une évaluation plus exhaustive est donc impérative.
Enfin, la robustesse des tests expérimentaux actuels est souvent insuffisante pour évaluer l’efficacité des mécanismes de défense dans des conditions du monde réel. Des facteurs tels que le bruit, la latence et les contraintes de ressources peuvent affecter la performance des mécanismes de défense et doivent être pris en compte dans les évaluations futures.
En conclusion, pour parvenir à une compréhension complète des risques et des mécanismes de défense efficaces, des études plus complètes et généralisables sont nécessaires. Ces études devraient adopter une approche multidimensionnelle, englobant une variété de modèles, de configurations et de conditions du monde réel. Seule une telle approche holistique permettra de développer des stratégies de défense robustes et efficaces, garantissant ainsi la sécurité des applications web qui intègrent des LLMs.
Qu’est ce que sense4data vous propose pour lutter contre ces menaces ?
Notre compréhension approfondie des complexités et nuances de divers types de données nous place dans une position crédible pour anticiper et contrer les risques de sécurité. En combinant des techniques avancées d’analyse, de surveillance et de protection, nous veillons à ce que les vulnérabilités potentielles soient identifiées et traitées avant qu’elles ne deviennent une menace. Nos solutions sont conçues pour offrir non seulement une performance optimale, mais aussi un maximum de sécurité sans compromis.
Pour en savoir plus sur l’éventail des compétences au sein de sense4data, cliquez ici.
Bibliographie
[1] Zhang, Q., et al. « A Survey on Transfer Learning, » 2010.
[2] Halfond, W., et al. « A Classification of SQL-Injection Attacks and Countermeasures, » 2006.
[3] Vaswani, A., et al. « Attention Is All You Need, » 2017.
[4] Hochreiter, S., & Schmidhuber, J. « Long Short-Term Memory, » 1997.
[5] Ganin, Y., et al. « Domain-Adversarial Training of Neural Networks, » 2016.
[6] Shahzad, M., et al. « Evaluating Android Anti-malware against Transformation Attacks, » 2012.
[7] Tramèr, F., et al. « The Space of Transferable Adversarial Examples, » 2017.
[8] Xu, W., et al. « Automatically Evading Classifiers, » 2016.